- /
- /
Описание модуля "Распознавание текста (Tesseract OCR)"
Данный модуль предназначен для распознавания текста при сканировании из карточки документа, поставляется только с коммерческими версиями СЭД. Для его работы в составе системы FossDoc используется стороннее программное обеспечение Tesseract, которое распространяется его разработчиками свободно по открытой лицензии. Для использования данного модуля требуется, чтобы он был включен в серверную лицензию FossDoc.
Далее будет рассмотрено:
Распознавание текста
Команды для распознавания текста находятся в меню кнопки Сканирование карточки документа. Для распознавания можно сначала отсканировать некоторый документ (или приложить уже отсканированный документ на закладку файлы)
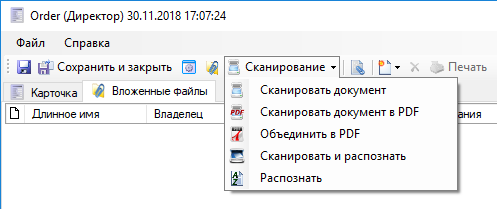
Допустим вы получили тем или иным образом некоторые отсканированные документы. Нажмите Сканирование/Распознать и выберите файлы, для которых необходимо распознать текст:
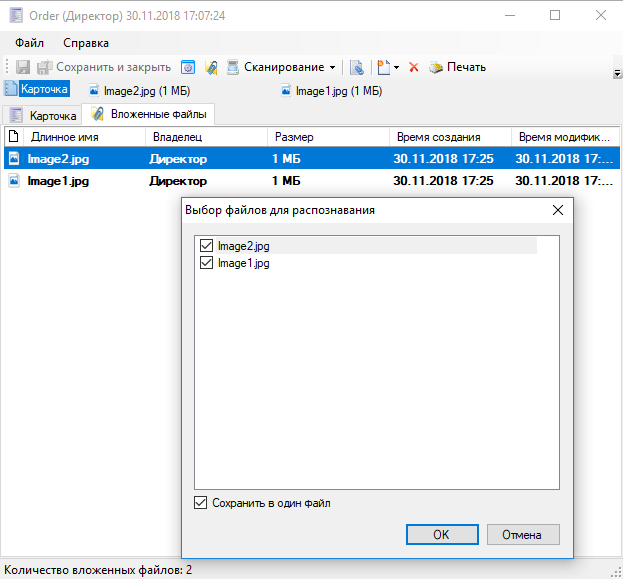
Если вы установите галочку "Сохранить в один файл", система объединит тексты из выбранных файлов в один файл. В результате будет создан файл в двух форматах - PDF и TXT. По умолчанию название файлов - "Document":
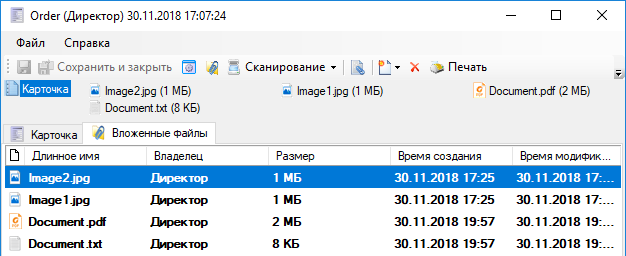
Аналогичным образом вы можете выбрать пункт Сканировать и распознать, чтобы сразу выполнить сканирование и распознавание отсканированного текста. После сканирования появится диалог:
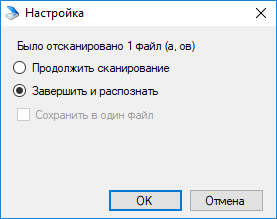
Выберите Завершить и распознать и нажмите ОК. Документ с распознанным текстом будет создан. Установите галочку Сохранить в один файл для объединения нескольких документов в один.
Дополнительные настройки модуля
Система по умолчанию настроена на распознавание текста на 3 языках: украинский, английский и русский. Если вы уверены, что для вашей работы требуется только один язык для распознавания, можете выбрать в настройках только его, - это несколько сократит время работы программы распознавания. Для того, чтобы выбрать один язык, перейдите в программе администрирования в Библиотеки документов/Сервер на закладку Библиотека сервера, нажмите "Настройка":
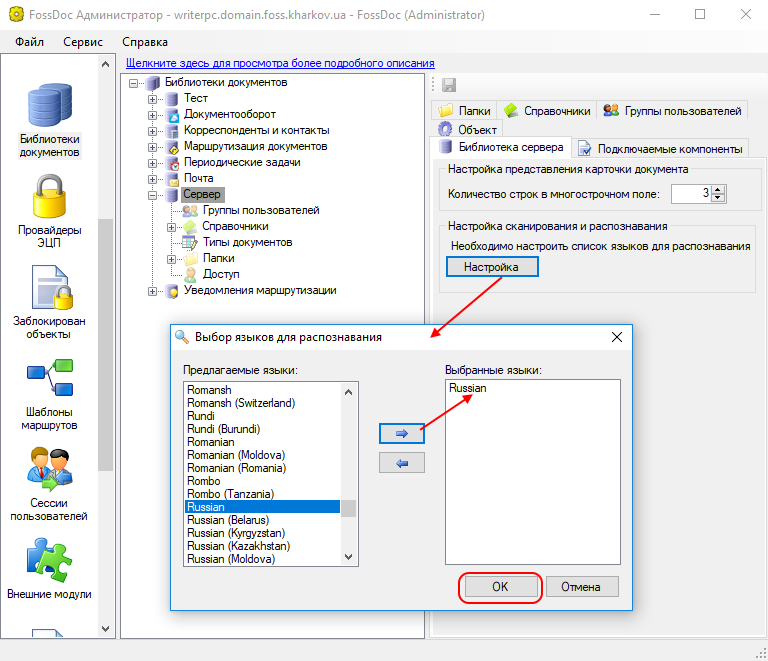
Выберите нужный язык и нажмите ОК.